![[Preparatórios] Concursos TI – Cabeçalho](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15165425/lancamento-ia-pro-tecnologia-da-informacao-cabecalho.webp)
Fala pessoal, estou aqui novamente com mais um artigo voltado para Mineração de Dados, porém falando agora de uma etapa anterior e muito importante, estou falando o pré-processamento de dados ! Vem comigo!! 😉
O pré-processamento de dados é uma etapa que ocorre antes da mineração e tem papel importante na adequação de dados para um padrão que possa ser absorvido durante as diferentes tarefas aplicadas na mineração de dados.
Os dados submetidos à mineração podem ser provenientes de diferentes fontes: sistemas transacionais, dados obtidos da web e não transacionais, podem ser estruturados, semiestruturados ou até não estruturados. Não raramente, os dados provenientes de diferentes fontes ou, em alguns casos, mesmo se provenientes de uma mesma fonte, apresentam algumas falhas ou são organizados de forma inadequada para serem submetidos à alguns algoritmos. Tais condições geram dificuldades no processo de descoberta de conhecimento e frequentemente levam ao fracasso da análise pretendida.
Sendo assim, é de suma importância a execução de procedimentos que pré-processem os dados, corrigindo inconsistências e, muitas vezes, agregando valor aos dados, de forma a dar condições ao processo de descoberta de conhecimento e chegar a resultados de qualidade. Problemas típicos associados à baixa qualidade de dados são ausência de valores, dados ruidosos, valores inconsistentes, atributos de naturezas distintas e redundância de dados.
Muitas dessas características não são evidentes no conjunto de dados, mas podem ser reveladas por procedimentos da análise exploratória.
Neste contexto, vamos analisar os seguintes procedimentos: limpeza, integração, transformação e redução dos dados.
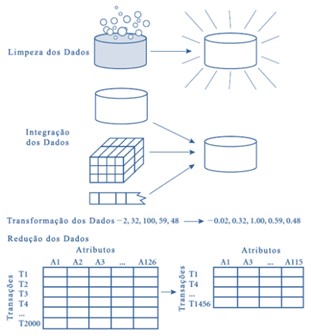
Limpeza dos Dados
É algo comum, que os dados sejam obtidos com diversas inconsistências: registros incompletos ou ausentes (missing values), valores errados e dados inconsistentes (noise values -valores ruidosos).
A etapa de limpeza dos dados visa eliminar estes problemas de modo que eles não influam no resultado dos algoritmos usados. As técnicas usadas nesta etapa vão desde a remoção do registro com problemas, passando pela atribuição de valores padrões, até a aplicação de técnicas de agrupamento para auxiliar na descoberta dos melhores valores. É uma etapa que demanda muito tempo no pré-processamento.
O problema de valores ausentes, podem ocorrer quando os atributos de um conjunto de dados não apresentam valores para determinados registros ou quando um conjunto de dados não possui valores para um atributo de interesse ou apresenta apenas valores agregados em relação àquele atributo. Esse problema pode acarretar dificuldades na produção de uma análise de qualidade ou pode inviabilizar um processo de análise se o algoritmo envolvido não puder lidar com a ausência de valores.
Nestes casos de ausência de valores (missing values), existem algumas alternativas:
- Exclusão do registro em que ocorre ausência de valor: Apesar de ser uma solução “radical” e simples, pode não ser efetiva em casos em que a quantidade de registros no conjunto de dados é pequena, ou quando há uma elevada quantidade de registros com dados ausentes.
- Preenchimento manual dos valores: É uma possibilidade, porém se faz necessário levar em consideração se será possível rodar novamente o processo de aquisição, sendo possível, recomenda-se a participação de especialistas no assunto do negócio onde os dados estão envolvidos. Neste caso, este especialista irá inserir estes dados, porém existe o risco de forçar uma tendência de valor informado, criando um viés, caso o especialista não tenha muito domínio sobre os dados envolvidos nos registros e no negócio.
- Preenchimento automático dos valores: Esta é uma solução que também necessita de cuidado para não criar um viés ou tendência de dados informados. Mas, como decidir qual dado será preenchido automaticamente? Bem, para isso temos algumas possibilidades, vem comigo!
- Estabelecimento de um valor constante, podendo ser com base no mais frequente atributo, quando preenchido;
- Valor médio ou mediano, considerando os demais valores presentes no atributo em questão;
- Resultado de um método de análise preditiva.
Para os valores ruidosos (noise values), geralmente causado por erros de medidas ou por valores discrepantes (outliers) dos valores normalmente encontrados nos demais registros. Geralmente percebe-se o ruído quando já se tem noção dos valores normalmente preenchidos em determinado domínio de dados e de repente surgem valores fora deste domínio. Para o tratamento de noise values, é possível utilizar duas abordagens, vejamos abaixo:
- Inspeção e correção manual: Uma ótima ferramenta para se achar tais valores, é se valer da análise exploratória, utilizando gráficos e analisando sua plotagem. Casos os valores ruidosos percebidos sejam poucos, é possível fazer uma correção manual neles. Caso sejam muitos, para fins de não distorcer a análise geral, é possível fazer um cálculo do valor médio, mediano ou de medidas separatrizes, com base nestes atributos preenchidos em outros registros e assim utilizar o resultado em substituição aos valores com ruído.
- Identificação e limpeza automática: Neste caso são utilizados algoritmos especializados, geralmente os que atuam em predição e agrupamento, para suavizar ou anular os ruídos dos dados existentes.
Bem, vou ficando por aqui para o artigo não ficar tão extenso. Logo mais estarei escrevendo a segunda parte deste tópico, onde irei abordar as outras etapas do pré-processamento de dados.
Até lá, forte abraço e bons estudos!!! 😉
=================================
Prof. Luis Octavio Lima

![[Preparatórios] Concursos TI – Post](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15165450/lancamento-ia-pro-tecnologia-da-informacao-post.webp)