![[Preparatórios] Concursos TI – Cabeçalho](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15165425/lancamento-ia-pro-tecnologia-da-informacao-cabecalho.webp)
Olá pessoal, estou de volta aqui para mais um artigo!
Hoje trago aqui alguns conceitos importantes e adicionais sobre Aprendizado de Máquina, inclusive sugiro a leitura prévia do artigo Aprendizado de Máquina: Conceitos.
O foco aqui é conhecermos o que vem a ser Overfitting e Underfitting, conteúdo que já começou a surgir explicitamente em alguns editais para concursos.
Os modos de aprendizado, mais frequentes, que se apresentam nas literaturas são o Não Incremental ou batch e o Incremental.
O modo não incremental se caracteriza pela totalidade dos conjuntos para treinamento, ou seja, toda amostra de dados já está disponível para uso.
No modo incremental o trabalho é feito pela atualização de hipóteses existentes, ou seja, sempre que surge um exemplo de dados novos (tuplas novas com seus valores de atributos), ele é então adicionado ao conjunto de treinamento.
No artigo indicado acima, eu falei sobre o que vem a ser o Aprendizado de Máquina (Machine Learning), falei também do modelo de aprendizado e da necessidade de se usar diferentes massas de dados, uma para aprendizado do modelo e outra para testes do modelo, porém, não temos garantia de que o modelo estará perfeito já na primeira rodada de testes, podendo apresentar vícios ou tendências de interpretação sobre os dados, até porque os dados são imperfeitos.
Devido a imperfeição dos dados, é comum que os algoritmos sejam testados e calibrados para fins de encontrar o melhor resultado no seu modelo com menos imperfeições possíveis. Porém essa é uma tarefa difícil e que exige cautela, para que não ocorram erros, que podem ser provocados por interpretações excessivas, induzindo o resultado a um determinado viés ou até mesmo focar em algo que não agregue muito valor ao resultado, ou que sobrecarregue o algoritmo com regras excessivas, chamamos este último de variância.
Quando uma hipótese está sendo avaliada e apresenta uma baixa capacidade de generalização, é possível que o modelo esteja demasiadamente ajustado (sobre-ajustado) aos dados de treinamento (overfitting). Nesse caso, também é dito que a hipótese memorizou ou se especializou nos dados de treinamento.
Neste caso, o modelo mostra-se adequado apenas para os dados de treino, como se o modelo tivesse apenas decorado os dados de treino e não fosse capaz de generalizar para outros dados nunca vistos antes.
No caso inverso, o algoritmo de aprendizagem de máquina pode induzir hipóteses que apresentam uma baixa taxa de acerto mesmo no subconjunto de treinamento, configurando uma condição de sub ajustamento (underfitting). Essa situação pode ocorrer, por exemplo, quando os exemplos de treinamento disponíveis são pouco representativos ou o modelo usado é muito simples e não captura os padrões existentes nos dados. O underfitting leva à um erro elevado tanto nos dados de treino quando nos dados de teste.
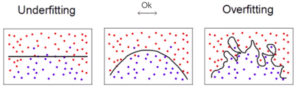
Por fim, podemos dizer então que o Overfitting está relacionado com o problema do viés, enquanto que o Underfitting está relacionado com o problema da variância.
É isso, um forte abraço e até o próximo artigo.
==========================================
Prof. Luis Octavio Lima

![[Preparatórios] Concursos TI – Post](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15165450/lancamento-ia-pro-tecnologia-da-informacao-post.webp)