![[APROVAÇÃO NÃO ESPERA EDITAL] Promo maio/junho e pós-copa – Cabeçalho](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/07/21105803/sua-aprovacao-nao-espera-edital-cabecalho-2lote.webp)
O Aprendizado de Máquina (machine learning), além de ser considerada uma subárea da Inteligência Artificial (AI), mantém relação com atividades realizadas na mineração de dados, porém atuando de forma ágil com a utilização de algoritmos específicos e recursos que possibilitam a elaboração de modelos, com base no treinamento aplicado aos dados. É equivocado afirmar que o aprendizado de máquina gera inteligência e por si só pode tomar decisões, não é bem assim.
Durante o aprendizado de máquina, existirá uma série de análises feitas por algoritmos específicos, em busca de encontrar padrões relevantes, porém isso não quer dizer que estamos produzindo conhecimento, na verdade, estamos agilizando parte do processo de obtenção da informação para fins de ganhar conhecimento, porém este último necessita da participação humana para que seja concretizada, podendo, em alguns casos, ter que rever as estratégias de treinamento sobre os dados , incluindo a “calibragem” nos parâmetros aplicados nas bibliotecas que utilizam tais algoritmos.
Segundo T. Michell:
“O aprendizado de máquina trata do projeto e desenvolvimento de algoritmos que imitam o comportamento de aprendizagem humano, com um foco principal em aprender automaticamente a reconhecer padrões complexos e tomar decisões.“
Uma estratégia muito utilizada é dividir a amostra de dados em um conjunto destinado ao treinamento e outra destinada aos testes. Essa partição no conjunto de dados tem por finalidade garantir a isenção na análise, de tal forma que os dados de testes não sejam os mesmos utilizados durante o treinamento, que tem a finalidade de criar o modelo de conhecimento. Os dados de teste serão aplicados no modelo de conhecimento obtido através do treinamento.
Logo abaixo, de forma simplificada, apresento duas figuras, onde a primeira divide a amostra em um conjunto de dados para treino e outro para teste. Perceba que no caso do treino a amostra geralmente é maior do que a de teste, isso para que os algoritmos utilizados possam extrair o máximo possível do padrões observados.

Figura 1: Dividindo a amostra
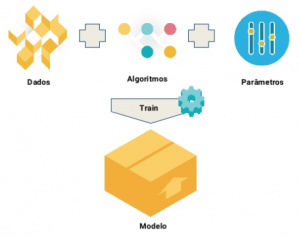
Figura 2: Executando o treinamento e obtendo o modelo de conhecimento
Imagine que uma organização deseje classificar dados em determinadas categorias, sendo que estes dados representam uma volumetria de 500 mil registros de um banco de dados que armazena os dados de transações de vendas on-line(e-commerce), ou seja, um volume considerável. Imagine agora que exista uma demanda para analisar os perfis dos clientes de acordo com o tipo de produto que eles consomem, porém a organização ainda não tem uma classificação definida para os perfis dos clientes.
Neste caso é possível fazer uso do Aprendizado de Máquina, através de algoritmos que possam inicialmente encontrar grupos de dados que se assemelhem pelas suas características. Nestes casos, os autores denominam esta forma de encontrar padrões, sem que haja valores definidos previamente para sua classificação, de aprendizado Não Supervisionado.
Um algoritmo muito conhecido para este tipo de descoberta de grupos (clusters) é o K-means (K-médias). Por se tratar de algoritmo de aprendizagem não-supervisionada, será informado para ele o valor de “k“, que corresponde a quantidade de clusters(grupos) que se deseja encontrar. Com base neste “k” informado, o algoritmo irá analisar todos os registros e agrupar em “k” grupos, levando em consideração a semelhança e característica de cada registro. Para que o K-means possa realizar os agrupamentos, existe um passo de transformar cada registro em um número (como se fosse um Id), alguns autores chamam esta atribuição de “rótulo”, para que então possam ser formados os clusters.
A partir da definição dos clusters(grupos), o algoritmo irá definir um valor médio(means) em cada grupo e este ponto é conhecido como centróide. A partir daí o algoritmo K-means fará o cálculo da distância entre cada elemento do grupo em relação ao centróide, afim deque todos os elementos fiquem bem próximos ao centróide localizado. Neste momento, possa ser que algum elemento mude de grupo, devido a proximidade dele em relação ao centróide do outro grupo. Vejamos abaixo uma sequência de figuras mostrando estes passos.

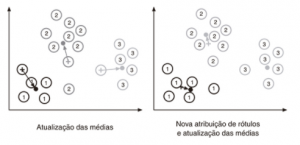
Figuras 3: Passos executados pelo K-means
O algoritmo K-means realiza várias iterações com a finalidade de manter cada um dos elementos o mais próximo possível do centróide, para fins de garantir maior coesão dos elementos de cada cluster (grupo).
A partir do resultado obtido através do algoritmo K-means, é possível definir os grupos encontrados e então rotular ou dar nomes a estes grupos e assim ter um modelo definido.
Quando o objetivo da organização é de classificar os registros de uma grande amostra de dados, se faz necessário estabelecer quais classes possíveis poderão existir e isso é feito a partir de um ou mais atributos da referida amostra. Pelo fato de já se conhecer a classificação pretendida, os autores denominam esta atividade de classificação de Aprendizado Supervisionado. Um algoritmo muito conhecido para classificação é o K-nn, que veremos mais detalhes no próximo artigo que escreverei.
Neste artigo apresentei alguns conceitos sobre o Aprendizado de Máquina, vejamos abaixo como esse assunto é cobrado em questões de concursos.
Questões de Concursos
(CEBRASPE/CESPE/IPHAN/ANALISTA I – ÁREA 7/2018)
Julgue o item que se segue, a respeito de tecnologias de sistemas de informação.
Na busca de padrões no data mining, é comum a utilização do aprendizado não supervisionado, em que um agente externo apresenta ao algoritmo alguns conjuntos de padrões de entrada e seus correspondentes padrões de saída, comparando-se a resposta fornecida pelo algoritmo com a resposta esperada.
As técnicas existentes na mineração de dados (Data Mining) são aplicadas no aprendizado de máquina, podendo ser numa abordagem supervisionada (quando se conhece padrões existentes e valores para comparação) e não supervisionada (quando não se conhece os padrões e características semelhantes dos registros em análise). A questão aborda o conceito de aprendizado supervisionado e portanto está errada.
Gabarito: Errado
(CEBRASPE/CESPE/TCE-PE/ANALISTA DE CONTROLE EXTERNO/2017)
Em relação à análise de agrupamentos (clusterização) em mineração de dados, julgue o item seguinte.
O método de clustering k-means objetiva particionar ‘n’ observações entre ‘k’ grupos; cada observação pertence ao grupo mais próximo da média.
O agrupamento é uma técnica utilizada na mineração de dados, e no caso do aprendizado de máquina recebe apoio do algoritmo k-means, com o objetivo de encontrar grupos(clusters) de registros que possuam características semelhantes. Para isso, o k-means irá utilizar uma amostra de “n” registros e calcular um ponto médio (chamado de centróide), que servirá de referência para que cada elemento(registro) analisado esteja próximo deste ponto, formando grupos específicos. Para iniciar o algoritmo, será necessário informar quantos grupos “k” deseja-se encontrar.
Gabarito: Certo
É isso, um forte abraço e aguardo você no próximo artigo.
Sugestão de leitura: CRISP-DM – Conceitos
Referências:
[1] GOLDSCHMIDT, Ronaldo; PASSOS, Emmanuel; BEZERRA,Eduardo. Data Mining – Conceitos, técnicas, algoritmos, orientações e aplicações.

![[APROVAÇÃO NÃO ESPERA EDITAL] Promo maio/junho e pós-copa – Post](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/07/21115954/sua-aprovacao-nao-espera-edital-post-2lote.webp)








Lido