![[OPERAÇÃO XEQUE-MATE] Preço R$ 54,90 – Cabeçalho](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/03/04163344/operacao-xeque-mate-cabecalho.webp)
Olá pessoal, eu aqui novamente. 🙂
Vamos de mais um artigo, desta vez com “mão na massa” em questões de concursos sobre um tópico que virou o queridinho dos editais parar cargos de TI: Mineração de Dados (Data Mining)…. vem comigo 😉
Antes de iniciar as questões, recomendo a leitura de alguns artigos aqui do blog relacionados a Data Mining, segue abaixo a lista dos links:
- Mineração de Dados: conceitos e características
- Aprendizado de Máquina: conceitos
- CRISP-DM: conceitos
Bem, vamos agora para as questões!
(CESPE/CEBRASPE/TCE-RJ/Analista de Controle Externo – TI/2021)
A respeito de mineração de dados, julgue o item que se segue.
No método de classificação para mineração de dados, a filiação dos objetos é obtida por meio de um processo não supervisionado de aprendizado, em que somente as variáveis de entrada são apresentadas para o algoritmo.
Comentário:
A classificação aplicada na mineração de dados parte do pré suposto que já existam rótulos de classificação existentes, ou seja, a partir de um modelo definido, é possível submeter algoritmos a um rol de registros e ter como resultado quantos registros se encaixam em determinada classificação. Neste cenário, pelo fato de já sabermos quais classes (ou rótulos) existem, estamos diante de um processo supervisionado, o que torna a questão errada ao afirmar que trata-se de um processo não supervisionado. Um exemplo seria uma seguradora que deseje saber se dentre os dados analisados de centenas de clientes, em relação ao risco de renovar o seguro, quantos são de risco: Alto, Médio ou Baixo. Perceba que ainda não se sabe quantos clientes se encaixam nestes riscos, mas se sabe que existem três categorias definidas (Alto, Médio e Baixo), ou seja, o fato de saber estes categorias torna o processo supervisionado.
Gabarito: Errado.
(CESPE/CEBRASPE/TCE-RJ/Analista de Controle Externo – TI/2021)
A respeito de mineração de dados, julgue o item que se segue.
No método de mineração de dados por agrupamento (clustering), são utilizados algoritmos com heurísticas para fins de descoberta de agregações naturais entre objetos.
Comentário:
Essa questão, diferente da outra, aborda o conceito sobre processo ou método não supervisionado, ou seja, não existe ainda um conjunto de rótulos existentes para se aplicar uma classificação ou seja, se faz necessário conhecer quais grupos (clusters) se formam a partir da análise de uma amostra de dados, utilizando-se algoritmos específicos, o K-means seria um deles. Estamos diante, neste caso, de um processo de descoberta (heurística) de grupos de dados por semelhança (agregações naturais). A partir dos grupos encontrados, e analisando o que cada grupo apresenta de característica com relação aos dados que o compõe, é possível estabelecer um rótulo (classe) que o identifique.
Gabarito: Certo.
(CESPE/CEBRASPE/TCE-RJ/Analista de Controle Externo – TI/2021)
Com relação a noções de mineração de dados e Big Data, julgue o item que se segue.
As regras de associação adotadas em mineração de dados buscam padrões frequentes entre conjuntos de dados e podem ser úteis para caracterizar, por exemplo, hábitos de consumo de clientes: suas preferências são identificadas e em seguida associadas a outros potenciais produtos de seu interesse.
Comentário:
O conceito da Associação se aplica nos casos em que um grupo de valores determina outro grupo, ou está associado a outro grupo ou faixa de valores, ou seja, quando A->B (A determina B), onde A e B são conjuntos de valores.
Um dos principais fatores que motivam o uso das regras de associação, são em casos em que as organizações desejam alavancar mais vendas em um determinado segmento comercial, oferecendo produtos que geralmente são consumidos, quando outros produtos são consumidos ou consultados. Para isso, são feitas consultas em grandes bases de dados históricas de vendas. Exemplos:
-
- “…quanto maior o tempo de espera pelo preparo de um prato, maior o consumo de bebidas..”
- “..se o filé à parmegiana é servido, então o arroz branco e batas fritas também são servidos.. (isso dará uma noção de estoque, a ser mantido, dos produtos associados)”
- “..homens que consultam sapatos na internet, geralmente consultam cintos…”
Gabarito: Certo.
(CESPE/CEBRASPE/TCE-RJ/Analista de Controle Externo – Controle Externo/2021)
Com relação a noções de mineração de dados e Big Data, julgue o item que se segue.
A descoberta de conhecimento em bases de dados, ou KDD (knowledge-discovery), é a etapa principal do processo de mineração de dados.
Comentário:
Alguns autores classificam o KDD (Descoberta de Conhecimento de Bases de Dados), como sendo uma abordagem bottom-up, onde a análise sobre os dados é realizada sem nenhuma suposição prévia, ou seja, os dados irão apontar os padrões e tendências encontrados. Trata-se de um processo interativo para identificar, nos dados analisados, novos padrões que sejam válidos, potencialmente úteis e interpretáveis. É um processo usado para identificação de padrões válidos, durante analise de grandes conjuntos de dados, podendo descobrir dados que sejam relevantes e importantes que podem ajudar ou facilitar na formação de opinião estratégica de uma organização. Segue abaixo figura mostrando as fases do KDD:
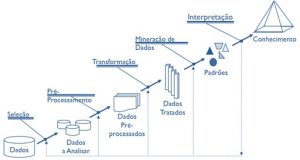
Uma das etapas do KDD é a mineração de dados, ou seja, a questão inverte este conceito, o que a torna errada.
Gabarito: Errado.
(CESPE/CEBRASPE/TCE-RJ/Analista de Controle Externo – Controle Externo/2021)
Com relação a noções de mineração de dados e Big Data, julgue o item que se segue.
Na mineração de dados preditiva, ocorre a geração de um conhecimento obtido de experiências anteriores para ser aplicado em situações futuras.
Comentário:
O passado e presente podem predizer o futuro, ou seja, a aplicação de algoritmos para analisar amostra de dados passados podem gerar um modelo onde ao ser aplicado em outras amostras de dados, podem ajudar a predizer um cenário futuro. Também chamada de análise preditiva.
Gabarito: Certo.
(CESPE/CEBRASPE/TCE-RJ/Analista de Controle Externo – Controle Externo/2021)
Com relação a noções de mineração de dados e Big Data, julgue o item que se segue.
A fase de implantação do CRISP-DM (cross industry standard process for data mining) só deve ocorrer após a avaliação do modelo construído para atingir os objetivos do negócio.
Comentário:
O CRISP-DM – Cross Industry Standard Process for Data Mining (Processo Padrão Inter-Indústrias para Mineração de Dados) e surgiu em 1996 como forma de apoio ao processo de descoberta do conhecimento, o famoso KDD – Knowledge Discovery in Databases (Descoberta de Conhecimento em Bases de Dados).
O CRISP-DM é constituído por 6 fases: Compreensão do Negócio, Compreensão dos Dados, Preparação dos Dados, Modelagem, Avaliação e Desenvolvimento (implantação).
Na fase de implantação do projeto de Mineração de Dados, leva-se em consideração que o modelo resultante da fase de modelagem precisa ser factível de ser usado, ou seja, o modelo para obtenção de conhecimento precisa, além ser aderente às necessidades da organização, necessita ser interpretável e com capacidade operacional. Nesta etapa será elaborado relatório final do processo, que apresenta os resultados obtidos e possíveis alternativas de ação no processo de descoberta de conhecimento aplicado na organização.
Gabarito: Certo.
Bem, vou ficando por aqui, desejo a você ótimos estudos!
Até o próximo artigo, abração! 😉
============================================
Prof. Luis Octavio Lima

![[OPERAÇÃO XEQUE-MATE] Preço R$ 54,90 – Post](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/03/04164337/operacao-xeque-mate-post.webp)







