![[Preparatórios] Concursos TI – Cabeçalho](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15172304/assinatura-de-verdade-concursos-tecnologia-ti-30off-cabecalho.webp)
Salve, salveeee !
Estou de volta em mais um artigo, ainda nos tópicos sobre Mineração de Dados (Data Mining), agora abordando conceitos sobre um dos algoritmos mais cobrados em provas de concursos sobre o referido tópico, que é o k-means.
Recomendo fortemente a leitura do último artigo que publiquei (Mineração de Dados – Agrupamento), afim de dar embasamento para este artigo de agora
Vem comigo 😉
O objetivo ao usar o k-means é detectar o conjunto de objetos(dados) “semelhantes”, chamados de grupos (clusters). Quando falo o termo “semelhante” estou querendo dizer “conjunto de dados que possuem características aproximadas”.
O k-means faz parte da família de algoritmos que pertencem ao aprendizado não supervisionado, ou seja, faz parte do ramo de aprendizado de máquina (Machine Learning), cujo objetivo é aprender sobre dados que ainda não possui uma classificação ou categorização (rótulos).
Ao usar o k-means tentamos, a partir da leitura dos dados, separar estes dados em k clusters (grupos), onde este k é estipulado pelo usuário antes de executar o algoritmo.
O k-Means usa o conceito de centróide. Dado um conjunto de dados, o algoritmo seleciona de forma aleatória k registros, cada um representando um agrupamento (clustering).
Para cada registro restante, é calculada a similaridade entre o registro analisado e o centro de cada agrupamento (centróide). O objeto é inserido no agrupamento em que ele mantenha menor distância em relação aos demais agrupamentos, ou seja, maior similaridade.
O centro do cluster é recalculado a cada novo elemento inserido. Veja o exemplo abaixo, onde foram formados 3 clusters, com o destaque para os centroides localizado em cada um dos clusters.
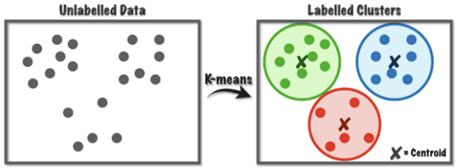
Então, de forma resumida, temos os seguintes passos no uso do k-means:
- Determinar o número de clusters desejados (k);
- Encontrar os centróides iniciais para cada cluster;
- Associar cada objeto de dados ao seu centróide mais próximo.
O algoritmo k-means funciona em repetidas iterações, até que os objetos de dados não mudem seus centros de clusters, o que significa que estão estabilizados nos seus respectivos grupos (clusters).
É isso aí pessoal, termino aqui mais um artigo e espero vocês na próxima publicação.
Mantenham o foco e bons estudos! 😉
=============================================
Prof. Luis Octavio Lima

![[Preparatórios] Concursos TI – Post](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15172341/assinatura-de-verdade-concursos-tecnologia-ti-30off-post.webp)







