![[APROVAÇÃO NÃO ESPERA EDITAL] Promo maio/junho e pós-copa – Cabeçalho](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/07/27090851/sua-aprovacao-nao-espera-edital-cabecalho-3lote.webp)
Olá Pessoal 😉
Neste artigo vou dar continuidade ao tópico abordado no artigo anterior (Data Lake: Conceitos e Características), agora explorando como o Data Lake pode ter sua estrutura organizada em diferentes zonas.
Como vimos no artigo anterior, o processo de ingestão de dados em um lago de dados se dá através da carga (Load), para depois serem feitas as transformações (Transform), sendo um pouco diferente do que estamos acostumados a ver quando estudamos sobre modelos dimensionais e Data Warehouse, onde o processo ETL (Extração, Transformação e Carga) é abordado.
Devido ao fato de termos que inicialmente fazer a carga dos dados e sendo estes dados com estruturas indefinidas (dados estruturados, não estruturados e semiestruturados), a boa prática é que a estrutura de Data Lake seja organizada de tal forma que os diferentes perfis de usuários sejam capazes de consumirem estes dados sem grandes problemas.
É justamente neste cenário onde as diferentes zonas no Data Lake surgem para facilitar. 😉
Existem diversas abordagens sobre como estas zonas são organizadas e definidas, porém existe um núcleo comum entre elas, sendo então descritas em 4 zonas: Transient Zone, Raw Data Zone, Trusted Zone e Refined Zone.
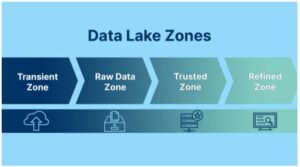
Vamos conhecer cada uma delas abaixo, vem comigo! 🙂
- Transient Zone: Trata-se como o próprio nome diz, de uma zona transitória, podendo ser considerada uma zona de arquivos temporários, até que seus dado sejam carregados na Raw Zone. Por exemplo, imagine que os dados ingeridos estejam num formato de dump ou arquivos compactados, esta zona pode ser usada para tornar estes dados acessíveis antes da carga para Raw Zone, onde após esta carga, tais arquivos podem ser apagados da zona transiente.
- Raw Data Zone: Também conhecida como simplesmente Raw Zone, tem como característica o armazenamento de dados em seu estado bruto, ou seja, no seu estado original, sem nenhum processamento ou tratamento. O objetivo é fazer a carga de forma rápida.
- Trusted Zone: Também chamada de Stage Zone, é zona que irá receber os dados já com algum tratamento, seja padronizando dados, tipos, uso ou não de máscaras, onde tais tratamentos são definidos pela área de negócio para seu consumo.
- Refined Zone: Aqui a zona é considerada especializada, onde os dados são enriquecidos não somente pelos dados da base original, mas podendo inclusive agregar dados de outras bases a depender do seu uso. Nesta zona, os dados geralmente assumem o formato relacional, podendo inclusive se apresentar em um modelo dimensional. Seu consumo também pode ser feito por aplicações e através de consultas via API.
A implementação dessas zonas facilita a aplicação de governança e qualidade de dados na arquitetura, permitindo um consumo preciso do grande volume e variedade de dados abarcado pelos Data Lakes.
Apesar destas zonas acima descritas serem uma espécie de “core” nos Data Lakes construídos por organizações públicas e privadas, é possível que cada uma destas organizações adaptem as suas estruturas a depender dos recursos e ferramentas que possuam, ou pelo viés do negócio.
Espero que tenham gostado, vou ficando por aqui e até o próximo artigo 😉
Ótimos estudos!
Prof. Luis Octavio Lima

![[APROVAÇÃO NÃO ESPERA EDITAL] Promo maio/junho e pós-copa – Post](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/07/27091228/sua-aprovacao-nao-espera-edital-post-3lote.webp)







