![[Preparatórios] Concursos TI – Cabeçalho](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15172304/assinatura-de-verdade-concursos-tecnologia-ti-30off-cabecalho.webp)
Fala pessoal, cá estou novamente com mais um artigo!! 😉
Bom, hoje, vamos trazer um tópico de certa forma antigo, mas que por muitas vezes é cobrado implicitamente no raciocínio de algumas questões sobre modelo relacional em banco de dados, estou falando as Regras de Codd, vem comigo!
O modelo relacional foi proposto na década de 70 por Edgard F. Codd.
Codd percebeu que seria possível aplicar as operações conhecidas na matemática para o manuseio de conjuntos sobre estruturas de dados. Operações como seleção, projeção, união, interseção e outras operações realizadas sobre os dados poderiam ser comprovadas através da teoria dos conjuntos (assunto esse muito explorado na Álgebra Relacional e muito utilizado no contexto de operações em banco de dados).
A partir daí, foi possível estabelecer um método formal e rigoroso para o tratamento das estruturas de dados, que até o momento eram desestruturados.
Para Codd, a motivação mais importante para o trabalho de investigação que resultou no modelo relacional foi o objetivo de fornecer uma fronteira clara entre a lógica e aspectos físicos do gerenciamento de banco de dados.
A proposta de Codd, descrita de forma resumida e sem a formalidade do modelo, se baseia em 3 aspectos básicos:
- Aspecto Estrutural: Dados que são percebidos como tabelas e nada além de tabelas;
- Aspecto de Integridade: As tabelas satisfazem a algumas regras de integridade, para fins de garantir a consistência dos dados, fazendo uso de limitadores e regras de restrição de dados.
- Aspecto Manipulativo: Possui operadores utilizados na manipulação dos dados armazenados nas tabelas, como por exemplo, realizar busca de dados na forma de projeção ou até de junção de dados em diferentes tabelas. Os operadores que se destacam neste aspecto e que são cobrados em provas de concursos, são: restrição, projeção e junção.
Vejamos abaixo, na forma de uma tabela, estes diferentes aspectos:
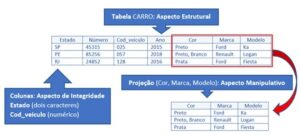
Perceba no exemplo acima, que a tabela CARRO, que representa a entidade CARRO, denota, para o modelo relacional, um Aspecto Estrutural. Nesta mesma tabela foram definidas colunas, sendo que algumas dessas colunas devem obedecer limites para fins de garantir o Aspecto de Integridade – por exemplo, a coluna Estado espera receber dois caracteres no seu preenchimento e a coluna Cod_veiculo um conteúdo numérico.
Podemos também perceber que foi aplicada uma operação de Projeção sobre os dados, mostrando apenas as colunas Cor, Marca e Modelo, o que denota um Aspecto Manipulativo. Esta projeção pode ter sido aplicada pra criar uma visão (view) específica dos dados, ou para servir de insumo em um relatório, enfim, pode ter sido feita por diversos motivos.
Ainda sobre os preceitos da Modelagem Relacional, descritos por Codd, outro ponto relevante que preciso destacar e que também é cobrado nas provas de concursos, trata-se das 12 Regras de Codd (na verdade são 13, pois vai da 0 até a 12), vejamos abaixo:
- Regra 0: Um SGBD relacional deve gerenciar seus dados usando apenas suas capacidades relacionais.
- Regra 1: Informação – Todas as informações em um banco de dados relacional são representadas explicitamente no nível lógico e de forma exatamente por valores em tabelas, ou seja, seus valores de coluna em linhas dentro das tabelas.

- Regra 2: Garantia de Acesso – Todos os valores atômicos(dados) de um banco de dados relacional devem ter a garantia de acesso, sendo tal acesso por combinação do nome da tabela, sua chave primária e o nome da coluna. A combinação destes dados forma um identificador único, mitigando problemas posteriores de interpretação da informação.
- Regra 3: Tratamento sistemático de nulos – Independente do tipo de dado que deva ser armazenado num campo, o valor nulo (null) é aquele que é diferente de uma cadeia de espaços vazios ou zeros, porém é suportado por qualquer SGBD;
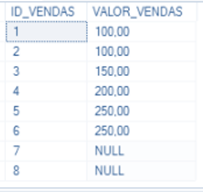
- Regra 4: Catálogo dinâmico baseado no modelo relacional – A descrição lógica do banco de dados(metadados) deve ser apresentada na mesma forma dos dados comuns, sendo possível, para acessar tais dados, usar a mesma linguagem regular que é usada no banco de dados;
- Regra 5: Sublinguagem ampla de dados – O banco de dados deve dar suporte à configuração do nível de inserções, atualizações e exclusões. No entanto, deve haver pelo menos uma língua cujas declarações são expressivas, por meio de uma sintaxe bem definida, como cadeias de caracteres, e que possibilite: definir dados, visualizar definições, manipular dados de forma interativa ou por programa, aplicar restrições de integridade, aplicar autorizações e estabelecer limites nas transações;
- Regra 6: Atualização de visualização – Qualquer visualização que possa ser atualizada teoricamente, o sistema deve permitir fazer, ou seja, o SGBD deve permitir a construção de diferentes visões de dados. Vale salientar que nem sempre as atualizações feitas em visões terão reflexo nas suas tabelas associadas.
- Regra 7: Inserção, atualização e exclusão de alto nível – O SGBD deve permitir que as operações de inserção, atualização e exclusão possam ser definida em diferentes níveis, fazendo uso da linguagem definida para manipulação de dados.
- Regra 8: Independência Física de Dados – Os aplicativos de uso em terminal não devem ser afetados quando houver mudanças nas estruturas ou no armazenamento dos dados;
- Regra 9: Independência Lógica de Dados – Os aplicativos de uso em terminal não devem ser afetados quando houver alterações na estrutura lógica das tabelas, ou nas visões criadas;

- Regra 10: Independência de Integridade – Possibilidade de criação de todas as definições de integridade relacional através da linguagem relacional e que elas sejam armazenadas no catálogo de sistema e não no nível de aplicação. As aplicações não devem ser afetadas por mudanças ocorridas nas restrições de integridade;
- Regra 11: Independência de Distribuição– Os usuários finais e aplicativos não devem ser afetados e nem devem conhecer sobre a localização dos dados;
- Regra 12: Não transposição das Regras – Como o sistema deve permitir acesso em baixo nível aos dados, as regras de integridade do banco de dados devem ser preservadas, de tal forma, que qualquer tentativa de acesso por usuário ou aplicação, sem respeitar as regras, seja impedida pelo SGBD.
É isso, sei que esse artigo foi extenso, mas o objetivo era trazer a mente este assunto que baseia os fundamentos e caraterísticas sobre Modelo Relacional, e muito se deriva deste assunto em outros tópicos tão importantes e que são cobrados nos editais de concursos públicos.
Um abração, até o próximo artigo, bons estudos 🙂
=============================================
Prof. Luis Octavio Lima

![[Preparatórios] Concursos TI – Post](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15172341/assinatura-de-verdade-concursos-tecnologia-ti-30off-post.webp)







