![[Preparatórios] Concursos TI – Cabeçalho](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15105050/hora-da-virada-tecnologia-da-informacao-20off-cabecalho.webp)
Fala pessoal, estamos aqui de volta para mais um artigo 😉
Neste artigo pretendo abordar alguns conceitos referentes às diferentes abordagens sobre arquiteturas em Data Warehouse (DW) defendidas por autores consagrados nas literaturas sobre o assunto e muito usadas para embasar questões de concursos.
Antes de iniciar este artigo, recomendo fortemente a leitura do artigo Conceitos básicos sobre Data Warehouse.
Bom, vamos lá! vem comigo!
A discursão sobre qual arquitetura seguir é bem abrangente na prática, os autores apresentam uma variação de opções, algumas bem teóricas e tradicionais, abordadas pelas questões de concursos, porém de algum tempo para cá isso tem evoluído e algumas provas têm cobrado alguns conceitos que antes não eram abordados.
Antes de abordar os tradicionais Inmon e Kimball, gostaria de trazer para você uma linha de raciocínio que servirá para melhor entender o que irei explicar mais adiante.
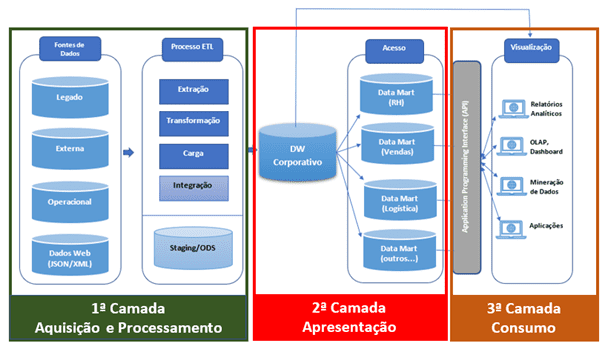
Muitos autores apresentam arquiteturas com duas ou três camadas, porém no caso da figura acima, trago para você uma abordagem em 3 camadas, pois ela apresenta de forma completa diversos componentes, porém envolvendo cada um deles em diferentes agrupamentos.
Na Arquitetura de três camadas, os sistemas operacionais contêm dados e o software para aquisição em uma camada, o Data Warehouse em outra camada, e a terceira camada inclui as aplicações e sistemas para consumo dos dados no DW, fazendo parte do universo BI. Vejamos.
1ª Camada: Software de aquisição de dados (back-end), que extrai dados dos sistemas legados e fontes externas, os consolida e resume, e depois os carrega no Data Warehouse. Nesta camada está também presente o sistema operacional escolhido para uso.
2ª Camada: O próprio Data Warehouse, que contém os dados e o software associados e que são apresentados para o consumo dos usuários finais.
3ª Camada: Software cliente (front-end) ou aplicação, que permitem aos usuários acessar e analisar dados a partir do DW. Geralmente usa uma camada de Middleware(utilizando API), para acesso ao DW com menor acoplamento entre as camadas.
Segundo Kimball:
A decisão de qual arquitetura implementar pode causar impactos quanto ao sucesso do projeto de um DW. Diversos fatores influenciam a escolha da arquitetura e implementação, entre elas o tempo para execução do projeto, a necessidade urgente de um DW, o retorno do investimento a ser realizado, a velocidade dos benefícios da utilização das informações , a limitação de recursos, a satisfação do usuário executivo, a compatibilidade com sistemas existente e os recursos necessários à implementação de uma arquitetura.
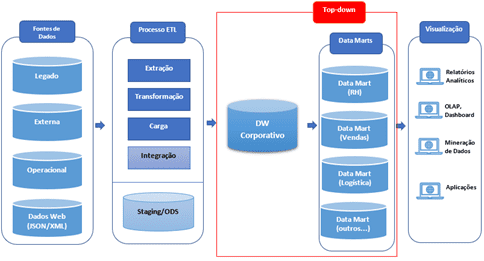
Abordagem “top down”
Segundo Inmon:
A implementação top down é conhecida como padrão inicial do conceito de DW. Ela requer maior planejamento e trabalho de definições conceituais de tecnologias completos, antes de iniciar o projeto DW. Neste tipo de arquitetura constrói-se, em primeiro lugar, o DW e depois se extrai os dados para os Data Marts.
Esta abordagem também chamada de Hub-and-spoke, apresenta uma forma de construção escalável e com formas de sustentação viável, geralmente usando um rito de construção iterativo e incremental nos assuntos abordados para composição o DW. Porém, existem as contrapartidas negativas, que é a alta redundância dos dados e a latência, ou seja, podemos ter problema de performance para entrega dos dados nas ferramentas de BI. Nesta abordagem, o DW terá em seu conteúdo dados atômicos e normalizados, e os Data Marts dados com alguns dados atômicos e dados sumarizados.
Vantagens:
- Herança da Arquitetura: todos os Data Marts originados de um DW utilizam a arquitetura e os dados do DW;
- Visão de Empreendimento: o DW concentra todos os negócios da empresa;
- Controle e Centralização de Regras: garante a existência de um único conjunto de aplicações ETL(Extract, Transform and Load)”
Desvantagens:
- Implementação muito longa;
- Alta taxa de risco;
- Expectativas relacionadas ao ambiente: a demora do projeto e a falta de retorno podem induzir expectativas nos usuários.
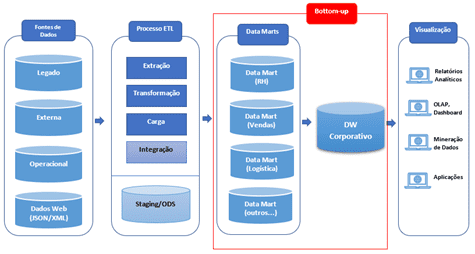
Abordagem “bottom up”
Segundo Kimball:
Devido ao custo e tempo necessários em uma implementação top down, a implementação botton up vem se tornando mais popular. O propósito é construir um DW incremental a partir do desenvolvimento de Data Marts independentes. Ela é bastante utilizada, pois possui um retorno de investimento muito rápido.
Vantagens:
- Implementação rápida;
- Retorno rápido;
- Enfoque inicial nos principais negócios;
Desvantagens:
- Perigo de Data Marts legados: a solução de Datar Marts independentes pode não levar em consideração à arquitetura numa visão global, inviabilizando futuras integrações;
- Dificuldade em obter a visão do empreendimento;
- Coordenação de múltiplas equipes e iniciativas;
- Procedimentos de ETL mais complexos.
Resumindo, a abordagem top down tem uma visão de cima para baixo, onde a partir de um DW pode-se expandir para Data Marts, ou seja, de uma visão global para uma visão departamental. Já na abordagem botton up, partimos de uma visão departamental para uma visão global, ou seja, de baixo para cima.
DW Centralizado e DW Federado
O DW Centralizado irá concentrar todos os dados, sem a utilização de Data Marts, ou seja, irá concentrar todos os dados da organização e seus departamentos, apresentando uma estrutura com dados normalizados, contendo dados atômicos e alguns já sumarizados. No tocante a sua rotina de carga, se torna mais simples para a equipe técnica pois as cargas se concentrarão em um único repositório, diferente no caso de uso de diversos Data Marts, simplificando também a questão do gerenciamento e administração de dados. Já em relação ao uso final se torna mais abrangente para os usuários, pois todos os dados encontram-se em um único local.
O DW Federado tem como premissa o uso de recursos já existente em diferentes lugares, ou seja, utiliza recursos analíticos espalhados por diversas regiões, cidades, países. Essa integração entre diferentes sistemas analíticos geralmente é feita por repasse de dados extraídos e consumidos por via de uma camada intermediária entre a origem e o fim. Essa camada, também conhecida como Middleware são oferecidas por diversas empresas do mercado especializado em soluções de integração e BI. Geralmente o formato do arquivo que irá trafegar entre a origem e o destino são XML e JSON. Estas fontes de dados distribuída podem ser Data Marts, sites, sistemas operacionais (OLTP), dentre outros.
Nesta abordagem, cada departamento vê um modelo de negócios de sua própria perspectiva. Por exemplo, um produto em Vendas pode ser definido como um material em Fabricação e equipamento em Gerenciamento de serviços. A fim de integrar esses sistemas heterogêneos que visam fornecer recursos analíticos em diferentes funções e departamentos, o data warehouse federado foi inventado.
Um data warehouse federado é uma abordagem prática para alcançar uma versão integrada em toda a organização, integrando as principais medidas e dimensões de negócios.
É isso pessoal, vou ficando por aqui, continuem no foco dos estudos e até o próximo artigo.
Abração 🙂
===============================
Prof. Luis Octavio Lima

![[Preparatórios] Concursos TI – Post](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15105055/hora-da-virada-tecnologia-da-informacao-20off-post.webp)







