![[Preparatórios] Concursos TI – Cabeçalho](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15172304/assinatura-de-verdade-concursos-tecnologia-ti-30off-cabecalho.webp)
Olá pessoal, vamos de mais um artigo na sequência sobre Tuning, assunto muito cobrado nos editais de concursos públicos para área de TI, fazendo parte dos tópicos sobre Administração de Banco de Dados.
Neste artigo abordarei conceitos sobre um dos principais vilões na degradação de performance em banco de dados, trata-se das operações realizadas em SQL, quando usada as boas práticas. Vem comigo 😉
A maioria dos problemas de performance não estão unicamente relacionados à arquitetura física do servidor SGBD. Na maioria das vezes eles estão na forma como as consultas são desenvolvidas em linguagem SQL.
Apenas para ajudar você a se situar em relação a que ponto estamos em um SGBD, trago abaixo uma figura onde o foco agora é na área circulada na figura, ou seja, no Processamento da Consulta.

É importante se preocupar em otimizar o servidor de banco de dados, porém melhorar o desempenho de consultas individuais pode ser ainda mais satisfatório. Existem várias formas de otimizar o banco e as consultas. Muitas vezes os bancos não são bem projetados e/ou não estão normalizados. Problemas de informações redundantes ou relacionamentos mal definidos provenientes de bases não normalizadas podem afetar de forma significante o desempenho das consultas existentes.
É importante conhecer as etapas que seguem desde o código escrito em SQL na aplicação ou chamada SQL, até ele ser de fato executado. Em uma visão de mais alto nível, o processamento do comando em SQL segue as seguintes etapas:
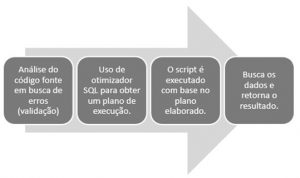
Estas etapas básicas se aplicam tanto para uma instrução select (consultas), como também em outros comandos SQL como insert, update e delete (inclusão, atualização e exclusão). As instruções update e insert podem conter instruções select, incorporadas, que fornecem os valores de dados a serem atualizados ou inseridos (alguns autores chamam de sub querys).
As etapas acima representam um caminho trival para execução de comando SQL. Duas figuras ilustres que fazem parte destas etapas são o Otimizador SQL e o Plano de Execução.
O Otimizador SQL avalia uma instrução SQL e indica qual o melhor método para executar a instrução com base no código SQL escrito e observando a existência de índices no banco de dados, ou seja, com base nos atributos, tabelas e condições descritas no comando SQL, será escolhido o melhor índice disponível. Porém, vale salientar, este otimizador pode variar na sua forma de avaliar e determinar o método de acordo com o fabricante do SGBD (MySQL, Oracle, SQL Server, PostgreSQL, DB2, dentre outros).
Já o Plano de Execução (ou plano da consulta) tem relação com o melhor caminho a ser escolhido para se chegar aos dados, sendo este caminho independente da tecnologia utilizada pelo fabricante do SGBD.
Um outro recurso que contribui muito para melhor performance das operações é a definição de índices que adotem a ordenação por atributos existentes nas operações. Mas, o que ocorre quando não índice que não contemple um ou mais atributos que são utilizados nas operações em SQL?
Neste caso, o que vai ocorrer é uma varredura completa na tabela que não possui índice associado a ela. Agora, imagine uma tabela com milhares de linhas, o tempo que isso vai levar. Esta operação de varredura completa é chamada de Full Tables Scan.
O otimizador de consultas do SGBD irá analisar a consulta e decidir se irá utilizar índice existente ou fazer varredura total na tabela. Para o uso de índices, algumas condições são impostas para o seu uso, como por exemplo:
- Atributos utilizados como chave primária;
- Atributos como sendo chave estrangeira;
- Atributos usados frequentemente para fazer joins entre tabelas;
- Atributos que são usados como condições de consulta;
Para concluir este artigo, trago abaixo alguns exemplos sobre a melhor forma de elaborar comandos SQL, com objetivo de obter melhor performance.
- Uso do Like:
- Evitar de usar o “%” como coringa nas consultas ajuda a ganhar performance, ou seja, quanto mais específica for a busca, mas rápido será.
Exemplo: SELECT NOME, DT_NASCIMENTO FROM FUNCIONARIO WHERE NOME LIKE ‘OCTAVIO’
A consulta acima é mais rápida do que se fosse assim:
SELECT NOME, DT_NASCIMENTO FROM FUNCIONARIO WHERE NOME LIKE ‘%OCTAVIO’
- Evitar de usar o “%” como coringa nas consultas ajuda a ganhar performance, ou seja, quanto mais específica for a busca, mas rápido será.
- Evitar operador OR:
- No lugar do OR, é mais eficiente usar o IN nas cláusulas WHERE. O OR terá que fazer diversas comparações e combinações, o que degrada performance. Vejamos um exemplo:
SELECT NOME, CURSO, DISCIPLINA FROM TURMA WHERE DISCIPLINA=’BANCO DE DADOS’ OR DISCIPLINA=’PROGRAMAÇÃO’ OR DISCIPLINA=’GOVERNANÇA’
A consulta acima é mais lenta do que usando o IN:
SELECT NOME, CURSO, DISCIPLINA FROM TURMA WHERE DISCIPLINA IN (’BANCO DE DADOS’, ’PROGRAMAÇÃO’, ’GOVERNANÇA’)
- Ordem das tabelas na cláusula FROM:
- A forma como as tabelas estão ordenadas na cláusula FROM contribui para uma melhor performance, dependendo de como o otimizador lê a instrução SQL. Uma estratégia é listar primeiro as tabelas menores e depois as maiores.
- Ordenações na cláusula WHERE:
- O foco deve ser nas condições mais restritivas, pois ela vai determinar o nível de performance da consulta SQL. Considera-se mais restritiva, a condição que vai retornar o menor número de linhas. Então a ordem ideal é primeiro as condições mais restritivas e em seguida as menos restritivas, ou seja, as que retornam mais linhas.
Este são alguns exemplos entre as diversas melhores práticas de escrita para otimizar consultas em SQL. Vejamos agora como este assunto é cobrado em questões de concurso.
Questões de Concursos
(CEBRASPE/CESPE/MEC/ADMINISTRADOR DE BANCO DE DADOS/2015)
Com relação à análise de desempenho e tunning de banco de dados, julgue o item subsequente.
Nas situações em que muitos usuários realizam inserções de forma concorrente, uma boa prática com relação ao planejamento do desempenho consiste em organizar as inserções de modo que elas envolvam a menor quantidade de tabelas possível.
Gabarito: Certo
Comentário:
A questão na verdade deseja saber se você tem noção sobre o fato de que o uso de toda as regras de normalização possam afetar a performance de determinadas operações no SGBD. É fato comprovado de que apesar de garantir restrições de integridade referencial, a normalização excessiva das tabelas, que geram novas tabelas relacionadas, podem degradar performance.
Diante deste contexto, a questão está certa, pois em inserções de dados de forma concorrente, ao lidar com tabelas normalizadas, muitas tabelas precisarão ser persistidas e muitos índices atualizados, podendo gerar lentidão nas operações.
Vou ficando por aqui, um forte abraço e até o próximo artigo 🙂
Ah, recomendo a leitura do artigo anterior onde também abordo conceitos de Tuning: Tuning em SGBDs – conceitos
Prof. Luis Octavio Lima

![[Preparatórios] Concursos TI – Post](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/01/15172341/assinatura-de-verdade-concursos-tecnologia-ti-30off-post.webp)







