![[APROVAÇÃO NÃO ESPERA EDITAL] Promo maio/junho e pós-copa – Cabeçalho](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/07/27090851/sua-aprovacao-nao-espera-edital-cabecalho-3lote.webp)
Fala pessoal, bom dia, boa tarde e boa noite!
Vamos de mais um artigo sobre um tema importante no contexto de banco de dados, big data e engenharia de dados, estou falando da Ingestão de Dados, uma fase importante na obtenção de dados para compor estruturas e arquiteturas definidas de dados, como por exemplo Data Warehouses e Datalakes (lago de dados). Vem comigo! 🙂
A Ingestão de Dados pode ser definida como sendo o processo usado na absorção de dados de uma grande variedade de fontes, fazendo em seguida a sua transferência para determinado destino onde então serão finalmente analisados.
Durante o processo de Ingestão de Dados serão escritos pipelines que irão mover os dados de um lugar para outro, porém, apesar de parecer simples tudo depende do formato e volume destes dados, uma vez que será possível escolher entre as estratégias de ETL – Extração, Transformação e Carga ou ELT – Extração, Carga e Transformação, sendo essa última muito comum quando o destino é um Datalake.
Existem prós e contras em relação a qual estratégia adotar, por exemplo, no caso do ETL os analistas e usuários de BI precisam aguardar toda conclusão do processo para então utilizar o dados no seu estágio final de transformação, geralmente em um Data Warehouse, e isso leva tempo.
Já no caso da estratégia ELT os dados são carregados imediatamente após a extração em um repositório centralizado, chamado de DataLake. Neste caso é frequente o uso de recursos de infraestrutura na nuvem devido a alta escalabilidade, devido a grande volumetria dos dados, o que já é esperado através dos conceitos relativos a Big Data.
Este grande volume de dados já carregado no datalake pode ficar disponível para diversos usuários com fins específicos, podendo inclusive fazer diversas transformações e refinamentos afim de construir um modelo de dados dimensional, se for o caso. Perceba que neste caso o tempo de disponibilização do dado é mais rápido do que em comparação a abordagem ETL.
Bem, mas, em se tratando de formas de Ingestão de Dados, vejamos baixo os dois tipos mais conhecidos:
Ingestão de dados em lote (batch)
A ingestão em lote ocorre, geralmente, de forma programada, ou seja, em horários agendados e isso tem um motivo principal: não comprometer o ambiente em produção que está ativo no momento. Geralmente são dados em grande volume e acumulados e que não precisa ser consumido em tempo real.
Neste tipo de ingestão é possível fazer a carga de forma full-loads, carregando todos os dados da fonte original em cada execução. Geralmente esta carga full onera muito o armazenamento e tempo de carga, pois trata-se da base de dados como um todo. A solução nestes casos é fazer uma carga full e as demais serem apenas cargas incrementais , ou seja, são carregados apenas os novos registros.
Ingestão de dados em tempo real (streaming)
A ingestão de dados ocorrendo em tempo real são úteis para cenários onde o dado precisa ser analisado enquanto é recebido, geralmente são dados utilizados em monitoramentos e críticos para tomada de decisão. Um conceito importante neste cenário é o de Change Data Capture (CDC), que é a captura do dados que sofreu alguma mudança.
Arquitetura Lambda
A arquitetura Lambda visa apresentar, de forma genérica, uma arquitetura que independe de tecnologia específica para coleta, armazenamento e processamento dos dados, utilizando as práticas recomendadas de ingestão em lote (batch) e em tempo real (streaming), sendo dividida em 3 grandes camadas, vejamos abaixo:
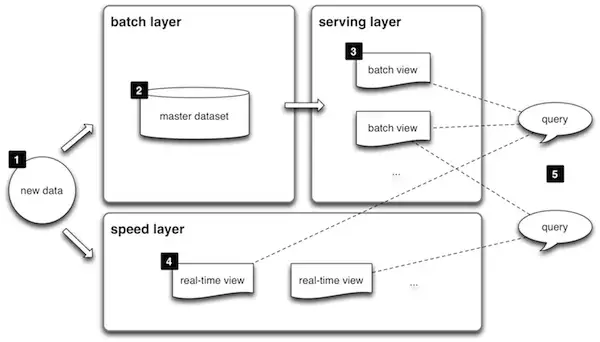
Batch Layer (Camada de Lote)
É a camada que armazena do dado bruto (raw data), podendo ser usado em processamentos posteriores. Como o dado é bruto, geralmente em alta volumetria, o processamento acaba sendo lento, ou seja, com alta latência.
Speed Layer (Camada de Velocidade)
É utilizada durante a ingestão de dados em tempo real (streaming). Nesta camada os logs de dados são processados de forma rápida, gerando visualização no curto prazo. O objetivo é que somente dados novos sejam consumidos nessa camada.
Serving Layer (Camada de Serviço)
Nesta camada os dados processados nas camadas anteriores são então indexados, possibilitando a criação de querys ad hoc com estes dados. As visualizações dos dados acabam sendo em baixa latência, ou seja, mais rápidas.
Por fim, caso queiram ler sobre conceitos de Data Lake, recomento a leitura dos seguintes artigos:
Vou ficando por aqui, um forte abraço e bons estudos 😉
====================================================
Prof. Luis Octavio Lima

![[APROVAÇÃO NÃO ESPERA EDITAL] Promo maio/junho e pós-copa – Post](https://blog-static.infra.grancursosonline.com.br/wp-content/uploads/2026/07/27091228/sua-aprovacao-nao-espera-edital-post-3lote.webp)







